- Objectives
- Participant
- Research Thrusts
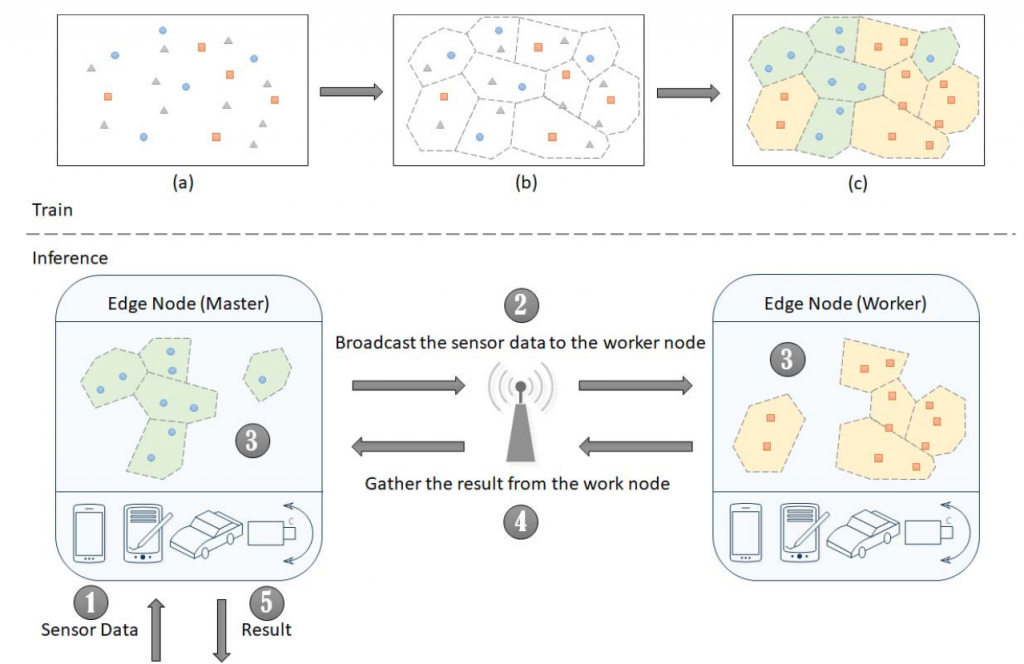
- 1- TeamNet: A Collaborative Inference Framework on the edge
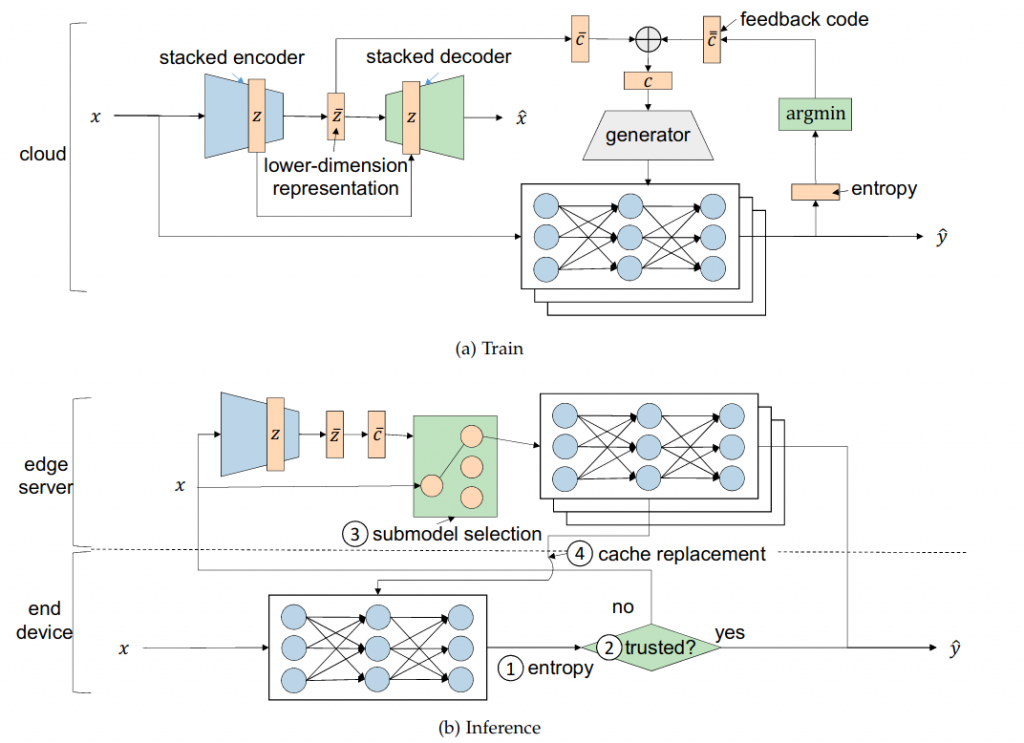
- 2- CacheNet: A Model Caching Framework forDeep Learning Inference on the Edge
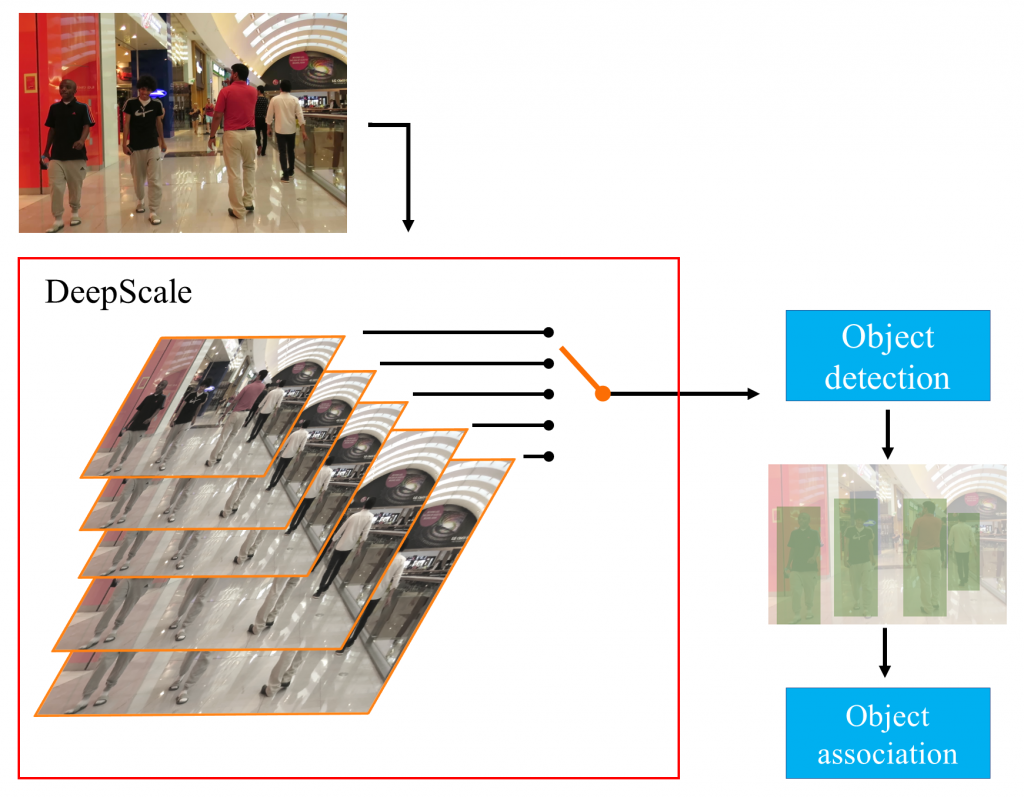
- 3- DeepScale: An Online Frame Size Adaptation Framework to AccelerateVisual Multi-object Tracking
- 4- MTMCT: Design and Implementation of a Multi-Target Multi-Camera Tracking Solution
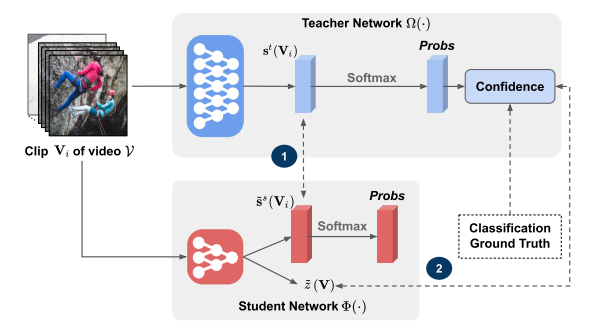
- 5- AttTrack: Online Deep Attention Transfer for Multi-object Tracking
- Publications
- Downloads
- Acknowledgment
Objectives #
Nowadays, neural networks have become the main part of machine learning tasks. To get high-performing networks, we require high computational resources that are far beyond mobile device capabilities. Shallow neural networks alone generally have poorer predictive accuracy compared to state-of-the-art deep neural networks, but they allow real-time prediction on edge devices, which makes them more suitable for edge computing. Towards applying those heavy models on mobile devices, the works we have done here are tailored to decrease the number of operations of models while keeping the original performance.
Participant #
- Yihao Fang (PhD)
- Shervin Manzuri Shalmani (MSc)
- Keivan Nalaie (PhD Student)
- Ruizhe Zhang (MEng Student)
Research Thrusts #
1- TeamNet: A Collaborative Inference Framework on the edge #
With significant increases in wireless link capacity, edge devices are more connected than ever, which makes possible forming artificial neural network (ANN) federations on the connected edge devices. Partition is the key to the success of distributed ANN inference while unsolved because of the nclear knowledge representation in most of the ANN models. We propose a novel partition approach (TeamNet) based on the psychologically-plausible competitive and selective learning schemes while evaluating its performance carefully with thorough comparisons to other existing distributed machine learning approaches. Our experiments demonstrate that TeamNet with sockets and transmission control protocol (TCP) significantly outperforms sophisticated message passing interface (MPI) approaches and the state-of-the-art mixture of experts (MoE) approaches. The response time of ANN inference is shortened by as much as 53% without compromising predictive accuracy. TeamNet is promising for having distributed ANN inference on connected edge devices and forming edge intelligence for future applications.
here
2- CacheNet: A Model Caching Framework forDeep Learning Inference on the Edge #
The success of deep neural networks (DNN) in machine perception applications such as image classification and speechrecognition comes at the cost of high computation and storage complexity. Inference of uncompressed large scale DNN models canonly run in the cloud with extra communication latency back and forth between cloud and end devices, while compressed DNN modelsachieve real-time inference on end devices at the price of lower predictive accuracy. In order to have the best of both worlds (latencyand accuracy), we propose CacheNet, a model caching framework. CacheNet caches low-complexity models on end devices andhigh-complexity (or full) models on edge or cloud servers. By exploiting temporal locality in streaming data, high cache hit andconsequently shorter latency can be achieved with no or only marginal decrease in prediction accuracy. Experiments on CIFAR-10 andFVG have shown CacheNet is58−217%faster than baseline approaches that run inference tasks on end devices or edge servers alone.
3- DeepScale: An Online Frame Size Adaptation Framework to Accelerate
Visual Multi-object Tracking #
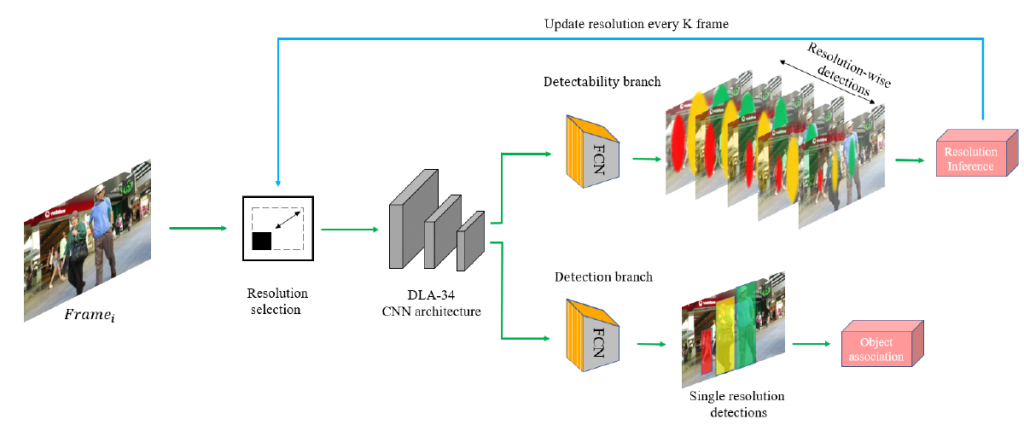
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today’s MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters. Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.3%) in tracking accuracy on the MOT15 dataset in one configuration.
4- MTMCT: Design and Implementation of a Multi-Target Multi-Camera Tracking Solution #
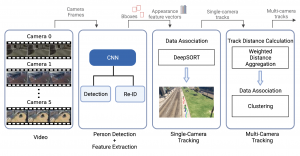
Multi-Target Multi-Camera Tracking (MTMCT) aims to continuously track multiple targets across video streams from multiple cameras of interest. To date, most MTMCT methods accomplish their tasks by first detecting targets and forming tracks within every single camera which then match single-camera tracks across all cameras in order to generate complete trajectories. Many approaches rely on two-stage single-camera trackers, which consist of two neural network models for object detection and feature extraction, to form single-camera tracks. However, the inference time of those solutions is usually slow, as the two models do not share features, and the re-ID model needs to be applied on each bounding box detected by the detector model. We propose an MTMCT solution by adopting a single-shot tracker, an effective data association method, and a weighted aggregation hierarchical clustering approach. Our solution outperforms the baseline approaches on a high-resolution simulated dataset and achieves a balance between performance and inference speed. See more details: report, repository.

5- AttTrack: Online Deep Attention Transfer for Multi-object Tracking #
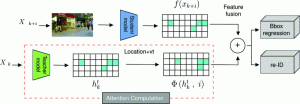
Multi-object tracking (MOT) is a vital component of intelligent video analytics applications such as surveillance and autonomous driving. The time and storage complexity required to execute deep learning models for visual object tracking hinder their adoption on embedded devices with limited computing power. In this paper, we aim to accelerate MOT by transferring the knowledge from high-level features of a complex network (teacher) to a lightweight network (student) at both training and inference times. The proposed AttTrack framework has three key components: 1) cross-model feature learning to align intermediate representations from the teacher and student models, 2) interleaving the execution of the two models at inference time, and 3) incorporating the updated predictions from the teacher model as prior knowledge to assist the student model. Experiments on pedestrian tracking tasks are conducted on the MOT17 and MOT15 datasets using two different object detection backbones YOLOv5 and DLA34 show that AttTrack can significantly improve student model tracking performance while sacrificing only minor degradation of tracking speed.
Publications #
- Fang, Yihao, Ziyi Jin, and Rong Zheng. “TeamNet: A Collaborative Inference Framework on the Edge.” In 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), pp. 1487-1496. IEEE, 2019.
- Fang, Yihao, Shervin Manzuri Shalmani, and Rong Zheng. “CacheNet: A Model Caching Framework for Deep Learning Inference on the Edge.” arXiv preprint arXiv:2007.01793 (2020).
- Keivan Nalaie and Rong Zheng. “DeepScale: An Online Frame Size Adaptation Approach to Accelerate Visual Multi-object Tracking.” arXiv preprint arXiv:2107.10404 (2021).
- Keivan Nalaie and Rong Zheng. “AttTrack: Online Deep Attention Transfer for Multi-object Tracking.” In 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2023 pp. 1654-1663. doi: 10.1109/WACV56688.2023.00170.
Downloads #
Acknowledgment #



